Le guide complet pour comprendre la réactivité en Shiny
Avez-vous déjà développé une appli Shiny devenue tellement compliquée que, par exemple :
- si on clique trop vite, les graphiques se mettent à clignoter et à se recharger à l’infini, ou bien
- certaines sorties sont calculées plusieurs fois de suite avant d’apparaître, et
- vous êtes incapable d’expliciter les liens de dépendances entre toutes les entrées, les données, les sorties, etc.
Alors ?
Moi ça m’est déjà arrivé.
En fait, ça m’arrive quasiment tout le temps.
Au début, on code, on code, on utilise la fonction reactive(), on ajoute quelques filtres.
Et puis on paramètre un filtre pour qu’il change la liste des choix d’un autre filtre.
Et puis on rajoute des calculs intermédiaires sur les données pour renseigner encore un troisième filtre.
Et puis on code des nouvelles features, par exemple cliquer sur un tableau pour faire apparaître un nouvel onglet.
Etc.
Plus vous en rajoutez, plus ça devient du spaghetti code !
Vous créez des liens de dépendance dans tous les sens.
Et au bout d’un moment, votre app devient fragile.
Si on clique trop vite sur les filtres, ils se mettent à clignoter dans tous les sens.
Quand on clique sur le tableau, ça recharge tellement de fois que vous préférez fermer les yeux pendant 10 secondes le temps que ça stabilise.
À chaque nouveau changement du code, vous avez peur que ça pète dans tous les sens.
:/
Bravo.
Vous avez créé un monstre.
Il est temps de changer de poste et de laisser le bouzin à votre successeur :D
Non sérieusement.
Vous êtes un type bien.
Donc vous allez faire une petite factorisation et revoir tout ça.
C’est l’objectif de cet article :
Vous aider à comprendre pleinement la réactivité, les liens de dépendances et d’interdépendances, et vous donner des stratégies afin de concevoir une application Shiny rapide, fluide, robuste, et facile à maintenir.
C’est quoi la réactivité ?
La réactivité permet de mettre à jour automatiquement une sortie (par exemple : un graphique, un tableau, une carte Leaflet, ou n’importe quel code HTML) lorsqu’une entrée est modifiée (un textInput, un selectInput, un jeu de données, etc.).
On va partir d’un exemple avec le jeu de données iris.
Vous pouvez directement copier-coller le code ci-dessous dans votre console R pour essayer :
server <- function(input, output, session) {
data <- reactive({
subset(
iris,
Species == input$species
)
})
output$plot <- renderPlot({
plot(
x = data()$Sepal.Length,
y = data()$Sepal.Width,
)
})
}
ui <- fluidPage(
titlePanel("iris"),
sidebarLayout(
sidebarPanel(
selectInput(
inputId = "species",
label = "Species",
choices = unique(iris$Species)
)
),
mainPanel(
plotOutput("plot")
)
)
)
shinyApp(ui, server)Vous pouvez retrouver le code ou visualiser l’application grâce aux liens ci-dessus.
On a une application très simple :
- Un filtre d’entrée :
input$species, qui permet de choisir l’espèce. - Un jeu de données intermédiaire :
dataqui est défini en utilisant la fonctionreactive()(on va y revenir). - Un graphique de sortie : Il utilise le jeu de données
data()pour tracer un graphique.
Tous les objets qu’on manipule ici sont des objets réactifs.
Un objet peut être réactif de deux manières différentes :
- Soit une entrée réactive
- Soit une sortie réactive
- Soit les deux.
Toutes les fonctions en Shiny qui terminent par Input (comme selectInput, textInput, shinyWidgets::pickerInput, dateInput, etc.) sont des entrées réactives.
On pourrait aussi dire que tous les objets à l’intérieur de input (dans notre exemple : input$species) sont des entrées réactives.
Toutes les fonctions en Shiny qui terminent par Output (comme plotOutput, dataTableOutput, leaflet::leafletOutput, etc.) sont des sorties réactives.
Pareil, on peut aussi dire que tous les objets qui s’écrivent output$nom (dans notre exemple : output$plot) sont des sorties réactives.
À retenir : Lorsqu’une sortie réactive utilise une entrée réactive dans son code, alors la sortie est automatiquement recalculée dès que l’entrée change.
Ensuite, on a les cas hybrides, qui sont à la fois des entrées et des sorties réactives.
Dans notre exemple, c’est le cas de data.
data est un objet réactif parce que nous avons utilisé la fonction reactive().
C’est à la fois une sortie réactive parce qu’il va être automatiquement recalculé dès que les entrées réactives qu’il utilise changent. Ici, dès que input$species va changer, alors data va être recalculé.
Mais c’est aussi une entrée réactive parce que dès que data va changer, alors l’affichage du graphique output$plot va être automatiquement recalculé.
Quand on change input$species, le jeu de données data est recalculé, ce qui provoque le recalcul du graphique output$plot.
Bon.
Là on a une application très simple. C’est ensuite que ça se complique.
Et si on n’avait pas utilisé reactive() ?
Ah oui ! Bonne question.
Si on écrit directement :
data <- subset(
iris,
Species == input$species
)Shiny n’est pas content et retourne une erreur :
Operation not allowed without an active reactive context. (You tried to do something that can only be done from inside a reactive expression or observer.)
En effet, on n’a pas le droit d’utiliser une valeur réactive en dehors d’un contexte réactif.
Un contexte réactif, ça va être :
- À l’intérieur de la fonction
reactive(oueventReactive) - À l’intérieur de la fonction
observe(ouobserveEvent) - À l’intérieur d’un bloc de sortie
output, dont la fonction démarre toujours parrender(renderPlotdans notre exemple)
Donc on n’a pas le droit d’utiliser input$species dans la nature.
Les fonctions de réactivité : req, isolate, etc.
Avant de parler stratégie ou de voir des exemples plus complexes, je pense que ça peut être utile de faire le tour des fonctions qui existent autour de la réactivité en Shiny.
Parfois, on prend des habitudes et on ignore complètement l’existence de certaines fonctions.
Par exemple, ça m’a mis des années avant de découvrir la fonction req ! Avant, je mettais des is.null() partout (et je ne suis pas le seul !).
Je vais aussi en profiter pour vous montrer des exemples où ces fonctions sont particulièrement adaptées.
La fonction reactive()
On en a déjà parlé, la fonction reactive() permet de créer un objet réactif qui est à la fois une entrée réactive et une sortie réactive.
Ça veut dire que l’objet va se mettre à jour automatiquement si les entrées qu’il utilise changent, et il va automatiquement déclencher la mise à jour des sorties où il est utilisé.
La fonction reactive() agit comme la déclaration d’une fonction :
- Tout ce qui est à l’intérieur n’existe que dans un environnement éphémère qui est détruit une fois la fonction terminée.
- On peut utiliser le mot-clef
returnpour retourner un résultat avant la fin du bloc de code. - Le code n’est pas exécuté tant que la fonction n’est pas appelée.
Ce dernier point est crucial et est une distinction importante avec la fonction observe() que nous allons voir juste après.
En effet, il est inutile de calculer un jeu de données qui est utilisé dans un onglet de votre appli tant que l’utilisateur ne clique pas sur cet onglet !
Exemple avec deux onglets :
Pour illustrer ce concept, je vais vous montrer un autre exemple avec deux onglets, un pour le jeu de données iris et l’autre avec le jeu de données mtcars.
Dans le chargement de mtcars, j’ajoute un temps d’attente de 5 secondes pour simuler le chargement d’un gros jeu de données.
Voici le code :
server <- function(input, output, session) {
data_iris <- reactive({
subset(
iris,
Species == input$species
)
})
data_mtcars <- reactive({
Sys.sleep(5) # On simule le chargement d’un gros jeu de données
mtcars
})
output$plot_iris <- renderPlot({
plot(
x = data_iris()$Sepal.Length,
y = data_iris()$Sepal.Width,
)
})
output$plot_mtcars <- renderPlot({
plot(
x = data_mtcars()$mpg,
y = data_mtcars()$wt
)
})
}
ui <- fluidPage(
tabsetPanel(
tabPanel(
title = "iris",
selectInput(
inputId = "species",
label = "Species",
choices = unique(iris$Species)
),
plotOutput("plot_iris")
),
tabPanel(
title = "mtcars",
plotOutput("plot_mtcars")
)
)
)
shinyApp(ui, server)Essayez l’application en cliquant sur le lien juste au-dessus.
Vous allez voir que quand vous visitez l’onglet mtcars, le graphique prend environ 5 secondes à charger, ce qui démontre que le reactive data_mtcars n’est pas lu tant qu’il n’est pas demandé.
Si ensuite vous changez d’onglet et revenez sur mtcars, il n’y a pas de rechargement puisque les données n’ont pas changé.
Enfin, il faut garder en tête que pour utiliser l’objet réactif ainsi créé, il faut mettre des parenthèses. D’où l’utilisation de data_iris()$Sepal.Length dans l’exemple ci-dessus. Après tout, comme on a dit que reactive() agissait comme la déclaration d’une fonction, c’est assez logique !
À retenir :
- La fonction
reactive()agit de manière similaire à la déclaration d’une fonction. - Le code à l’intérieur d’une fonction
reactive()n’est pas lu tant que le reactive en question n’est pas appelé. - Il faut rajouter des parenthèses pour appeler la variable réactive. Par exemple :
data().
La fonction eventReactive()
Et si on ne souhaitait PAS que notre objet soit réactif à tous les filtres ?
Par exemple :
- Quand vous commencez à accumuler les filtres sur vos données,
- Et que certains filtres contiennent des centaines de choix possibles,
- Et que le recalcul des données prend plusieurs secondes (rapide, mais pas instantané non plus !)
Par exemple :
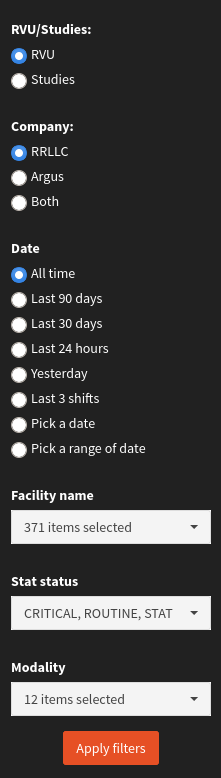
À chaque fois que l’utilisateur touche un filtre, ça recalcule pendant plusieurs secondes.
Alors si on doit toucher 5 ou 6 filtres, ou même si on doit cocher 10 cases dans un selectInput, ça peut vite devenir très pénible !
Dans ce cas, on va préférer ajouter un bouton « Valider » ou « Filtrer », et c’est seulement quand on clique sur ce bouton que le calcul est enclenché.
Exemple avec un bouton :
Voici le code de notre premier exemple mis à jour :
server <- function(input, output, session) {
data <- eventReactive(input$submit, {
subset(
iris,
Species == input$species
)
}, ignoreNULL = FALSE)
output$plot <- renderPlot({
plot(
x = data()$Sepal.Length,
y = data()$Sepal.Width,
)
data()
})
}
ui <- fluidPage(
titlePanel("iris"),
sidebarLayout(
sidebarPanel(
selectInput(
inputId = "species",
label = "Species",
choices = unique(iris$Species)
),
actionButton(
inputId = "submit",
label = "Submit"
)
),
mainPanel(
plotOutput("plot")
)
)
)
shinyApp(ui, server)Il y a deux changements :
- J’ai ajouté un
actionButtondans la partie UI. - J’ai remplacé la fonction
reactive()par la fonctioneventReactive().
Vous remarquerez en essayant l’application que le graphique ne se met pas à jour tant que vous ne cliquez pas sur le bouton.
L’idée de eventReactive est de spécifier les objets qui permettront de déclencher le calcul.
Ainsi, le calcul de data se déclenchera seulement si on clique sur le bouton ET qu’on a besoin de data pour l’affichage. Cette 2e condition vient toujours du fait qu’un reactive n’est pas calculé tant qu’on ne l’appelle pas.
Vous noterez que j’ai rajouté un argement ignoreNULL = FALSE à mon eventReactive().
Les arguments de eventReactive
En effet, cette fonction contient deux arguments très utiles par moment :
ignoreNULL(estTRUEpar défaut) : Permet de ne pas déclencher le calcul si l’input est NULL (ou vaut 0 dans le cas d’unactionButton). Si j’avais gardé la valeur par défaut, alors le calcul ne se serait pas déclenché (et le graphique pas affiché) tant que je ne clique pas sur le bouton une première fois.ignoreInit(estFALSEpar défaut) : Permet de ne pas déclencher le calcul lorsque leeventReactive()est créé.
Dans mon cas, je veux que lorsque l’utilisateur arrive sur la page, il voit le graphique directement sans avoir à cliquer. Donc ignoreInit = FALSE et ignoreNULL = FALSE.
L’intérêt principal ici est que le graphique ne se recharge pas tant qu’on ne clique pas sur le bouton.
Ça veut dire qu’en tant qu’utilisateur, j’ai tout le temps pour choisir mes filtres (supposons qu’il y en ait plein !) sans avoir une appli qui se rafraîchit à chaque clic.
On reste sur quelque chose de simple.
À retenir :
- On utilise
eventReactivelorsqu’on souhaite que la variable réactive réagisse à un nombre limité d’entrées réactives, typiquement le clic sur un bouton. - À l’instar de
reactive,eventReactiven’est lu que lorsque la variable est nécessaire. - La fonction
eventReactivecontient deux argumentsignoreNULLetignoreInità connaître.
La fonction observe()
La fonction observe() est très versatile et vous sera utile dès que vous souhaitez faire une opération qui dépend de plusieurs variables réactives.
En effet, la fonction observe() crée un contexte réactif, ce qui donne l’autorisation d’utiliser des variables réactives, et ensuite vous êtes libre de faire ce que vous voulez :
- Enregistrer une information en base
- Afficher une information sur l’application : du HTML, une fenêtre modale, un appel JavaScript, etc.
- Définir des sorties (on peut mettre un
output$plot <-à l’intérieur d’unobservepar exemple) - Etc.
Exemple d’enregistrement d’une information en base :
Prenons un exemple sur le premier cas. Je souhaite enregistrer toutes les occurrences de clic sur le bouton « Submit ».
Voici le code de ma nouvelle application :
server <- function(input, output, session) {
data <- eventReactive(input$submit, {
subset(
iris,
Species == input$species
)
}, ignoreNULL = FALSE)
observe({
if (input$submit > 0) {
log <- data.frame(
clic = "submit",
n = input$submit,
time = Sys.time()
)
write.table(log,
file = "logs.csv",
sep = ",",
append = TRUE,
row.names = FALSE,
col.names = FALSE)
}
})
output$plot <- renderPlot({
plot(
x = data()$Sepal.Length,
y = data()$Sepal.Width,
)
data()
})
}
ui <- function() {
fluidPage(
titlePanel("Coucou"),
sidebarLayout(
sidebarPanel(
selectInput(
inputId = "species",
label = "Species",
choices = unique(iris$Species)
),
actionButton(
inputId = "submit",
label = "Submit"
)
),
mainPanel(
plotOutput("plot")
)
)
)
}
shinyApp(ui, server)J’ai seulement rajouté un bloc observe() dans la partie server.
Ce bloc peut être vu comme une sortie réactive.
Il va être réexécuté à chaque fois qu’une des entrées réactives qu’il utilise sera modifiée.
Dans notre cas : À chaque fois que l’utilisateur clique sur le bouton.
Ici j’enregistre l’information dans un fichier CSV, mais ce serait pareil pour une base de données.
A contrario de la fonction reactive(), le code à l’intérieur d’une fonction observe() est lu dès le démarrage de la session.
Si le code à l’intérieur du observe() est long à exécuter, mais pas nécessaire immédiatement, on ralentit l’application au démarrage pour rien.
Pour rien ?
Pas forcément en fait.
Parfois, on va préférer un temps de chargement plus long au démarrage pour favoriser une navigation plus fluide par la suite.
Ça dépend beaucoup de l’application en question et des attentes des utilisateurs.
Petite subtilité dans notre exemple : on fait un test sur input$submit en testant pour qu’il soit plus grand que 0, afin d’éviter d’enregistrer l’information tant que le bouton n’a pas été cliqué.
Mais qu’est-ce qui se passe si l’input n’existe pas encore ? Là ça marche, mais peut-être qu’on a juste du bol.
On verra comment rendre l’application plus robuste avec la fonction req() ou avec observeEvent.
Pour l’instant ça tourne bien dans notre petite application.
À retenir :
- La fonction
observe()est utilisée pour faire des opérations utilisant des objets réactifs. - Le code à l’intérieur de
observe()est lu dès le démarrage de la session. - Pour la raison évoquée dans le point précédent, il faut vérifier que les entrées réactives utilisées existent bien.
La fonction observeEvent()
observeEvent est à observe ce que eventReactive est à reactive.
L’idée est la même.
Au lieu d’être réactif à TOUS les inputs à l’intérieur du bloc de code, on spécifie une seule entrée réactive.
Exemple d’enregistrement d’une information en base :
En fait, le code que j’ai présenté dans la section précédente serait plus adapté avec un observeEvent puisqu’il permettrait de se passer de la condition if :
server <- function(input, output, session) {
data <- eventReactive(input$submit, {
subset(
iris,
Species == input$species
)
}, ignoreNULL = FALSE)
observeEvent(input$submit, {
log <- data.frame(
clic = "submit",
n = input$submit,
time = Sys.time()
)
write.table(log,
file = "logs.csv",
sep = ",",
append = TRUE,
row.names = FALSE,
col.names = FALSE)
})
output$plot <- renderPlot({
plot(
x = data()$Sepal.Length,
y = data()$Sepal.Width,
)
data()
})
}
ui <- function() {
fluidPage(
titlePanel("Coucou"),
sidebarLayout(
sidebarPanel(
selectInput(
inputId = "species",
label = "Species",
choices = unique(iris$Species)
),
actionButton(
inputId = "submit",
label = "Submit"
)
),
mainPanel(
plotOutput("plot")
)
)
)
}
shinyApp(ui, server)Même plus besoin d’avoir la condition if, puisque par défaut la fonction observeEvent vient avec l’argument ignoreNULL = TRUE.
Tant que le bouton n’est pas cliqué, le code n’est pas lu.
À l’instar de eventReactive, il existe aussi un argument ignoreInit qui est FALSE par défaut.
Comme pour observe, le code de observeEvent est lu dès le lancement de la session. Mais comme en général la variable réactive qui permet de déclencher le code est NULL au lancement, ça ne pose pas de problème pour la performance.
Vous remarquerez qu’on a codé deux fois la même application, mais une fois avec observe, et une fois avec observeEvent.
Ça montre qu’il n’y a pas qu’une seule manière de coder vos applis. Néanmoins, dans la plupart des situations, il y a une manière qui se démarque des autres en étant plus adaptée ou plus performante.
À retenir :
- On utilise
observeEventlorsqu’on souhaite que le morceau de code ne réagisse qu’à un nombre limité d’entrées réactives, typiquement le clic sur un bouton. - Le code à l’intérieur de
observeEvent()est lu dès le démarrage de la session, sauf siignoreInitvautTRUE. - La fonction
observeEvent()contient deux argumentsignoreNULLetignoreInità connaître.
La fonction reactiveValues()
Quoi ? Encore une fonction pour créer une variable réactive ?!
Bah oui.
reactive() c’est très bien, mais ça ne crée pas tout à fait une variable réactive.
En effet, on ne peut pas modifier data() une fois qu’on l’a créé. Plus exactement, la seule manière de modifier data() consiste à refaire le calcul à l’intérieur du reactive().
Et si je veux :
- faire un calcul différent,
- rajouter une colonne,
- mettre à jour une valeur,
- ou appliquer des filtres supplémentaires…
Comment on fait ?
La problématique classique, c’est quand le calcul dans le reactive() est long.
Quand ça prend au moins quelques secondes.
Typiquement une requête SQL.
Exemple avec plusieurs variables reactive() :
La première approche, c’est déjà d’utiliser plusieurs fois la fonction reactive().
Par exemple, une variable reactive() pour taper dans la base, et une pour appliquer les filtres.
Prenez ce code :
server <- function(input, output, session) {
data <- reactive({
Sys.sleep(5) # On simule une grosse requête SQL
iris
})
filtered_data <- reactive({
subset(
data(),
Species == input$species
)
})
output$plot <- renderPlot({
plot(
x = filtered_data()$Sepal.Length,
y = filtered_data()$Sepal.Width,
)
})
}
ui <- fluidPage(
titlePanel("iris"),
sidebarLayout(
sidebarPanel(
selectInput(
inputId = "species",
label = "Species",
choices = unique(iris$Species)
)
),
mainPanel(
plotOutput("plot")
)
)
)
shinyApp(ui, server)Dans cette application, j’ai rajouté un temps d’attente de 5 secondes au chargement du jeu de données pour simuler une requête SQL.
Donc quand vous chargez l’appli, ça prend 5 secondes avant que le graphique ne s’affiche.
Dans ce cas, si on n’avait qu’un seul reactive(), il faudrait refaire systématiquement la requête de 5 secondes à chaque fois qu’on change le filtre.
Mais heureusement, j’ai été plus malin (!), j’ai créé un deuxième reactive() qui utilise le résultat de la requête et qui applique le filtre. Ainsi, si on change le filtre, pas besoin de refaire la requête.
Bon, ça c’est un cas simple qui consiste à morceler les reactive() en plusieurs fois pour éviter de refaire des opérations pour rien.
Exemple de modification des données :
L’autre cas d’usage plus complexe, ça va être celui où on veut faire un tout petit changement au jeu de données : On veut changer une valeur ou rajouter une ligne.
L’approche naïve, ce serait d’enregistrer le changement dans la base de données, et de refaire la requête.
Sauf que ça va être long pour rien, ça va utiliser des ressources sur la base, et l’utilisateur va pas comprendre pourquoi c’est lent.
Reprenons l’exemple où on enregistre les clics sur le bouton dans un fichier CSV. Cette fois-ci, je veux afficher le tableau des logs et le mettre à jour automatiquement à chaque clic.
Voici un premier essai avec eventReactive :
server <- function(input, output, session) {
observeEvent(input$submit, {
log <- data.frame(
clic = "submit",
n = input$submit,
time = Sys.time()
)
write.table(log,
file = "logs.csv",
sep = ",",
append = TRUE,
row.names = FALSE,
col.names = FALSE)
})
logs <- eventReactive(input$submit, {
if (file.exists("logs.csv")) {
Sys.sleep(2)
read.table(
"logs.csv",
sep = ",",
colClasses = "character",
col.names = c("clic", "n", "time")
)
}
}, ignoreNULL = FALSE)
output$logs_table <- renderTable({
if (!is.null(logs())) {
logs()
}
})
}
ui <- fluidPage(
titlePanel("Coucou"),
sidebarLayout(
sidebarPanel(
actionButton("submit", "Submit")
),
mainPanel(
tableOutput("logs_table")
)
)
)
shinyApp(ui, server)Ça commence à devenir plus compliqué.
D’abord, on a le observeEvent qui permet d’enregistrer les clics sur le bouton dans le fichier CSV.
Ensuite, on a une variable réactive logs() qui va lire le fichier CSV. Cette variable va être rafraîchie à chaque fois qu’on clique sur le bouton.
J’ai volontairement rajouté un temps d’attente de 2 secondes pour simuler le fait que le fichier soit lourd ou qu’on fasse une requête lente sur une base de données.
Si vous utilisez cette application, vous allez voir qu’à chaque fois que vous cliquez sur le bouton, le tableau se rafraîchit, sauf que ça prend 2 secondes puisque ça recharge complètement le fichier en entier.
Clairement, on fait des calculs pour rien et on aimerait bien juste rajouter la dernière ligne à notre variable réactive logs().
Sauf que.. on ne peut pas modifier un reactive().
D’où l’intérêt d’utiliser reactiveValues() dans ce cas.
Autre problème
Vous aurez peut-être remarqué que le observeEvent et le reactiveValues réagissent sur la même entrée réactive input$submit.
Si le reactiveValues est calculé avant le observeEvent, alors le tableau ne sera pas le bon.
L’ordre des blocs de code n’a aucun impact sur qui est calculé en premier.
En fait, on pourrait utiliser l’argument priority de ces fonctions, mais c’est en général par là que commencent les ennuis et le spaghetti code.
On va voir que utiliser reactiveValues permet de résoudre ce problème aussi.
Le même exemple avec reactiveValues() :
server <- function(input, output, session) {
values <- reactiveValues(
logs = NULL # Initialisation
)
observe({
if (file.exists("logs.csv")) {
Sys.sleep(2)
values$logs <- read.table(
"logs.csv",
sep = ",",
colClasses = "character",
col.names = c("clic", "n", "time")
)
} else {
NULL
}
})
observeEvent(input$submit, {
log <- data.frame(
clic = "submit",
n = input$submit,
time = as.character(Sys.time())
)
write.table(log,
file = "logs.csv",
sep = ",",
append = TRUE,
row.names = FALSE,
col.names = FALSE)
if (is.null(values$logs)) {
values$logs <- log
} else {
values$logs <- rbind(
values$logs,
log
)
}
})
output$logs_table <- renderTable({
if (!is.null(values$logs)) {
values$logs
}
})
}
ui <- fluidPage(
titlePanel("Coucou"),
sidebarLayout(
sidebarPanel(
actionButton("submit", "Submit")
),
mainPanel(
tableOutput("logs_table")
)
)
)
shinyApp(ui, server)Je pense que ce bout de code mérite quelques explications.
Dans un premier temps, j’initialise mon reactiveValues :
values <- reactiveValues(
logs = NULL # Initialisation
) reactiveValues s’utilise exactement comme si vous déclariez une liste : vous mettez les objets de la liste les uns après les autres séparés par des virgules. Ensuite, les objets sont accessibles en utilisant values$logs ou values[["logs"]].
Dans notre exemple on n’a qu’un seul objet à l’intérieur, mais on pourrait ajouter d’autres variables. Toutes les variables à l’intérieur du reactiveValues sont indépendantes et vivent leurs vies de leur côté.
Ça veut dire qu’il est inutile de créer plusieurs reactiveValues(). Le seul intérêt serait pour organiser votre code et réunir des variables similaires ensemble. Personnellement, je préfère avoir une seule liste que j’appelle values.
Ensuite, on n’est pas obligés de déclarer la valeur tout de suite. Potentiellement, je pourrais écrire values <- reactiveValues(), et plus tard j’assigne une valeur à values$logs.
Mais j’aime bien déclarer les valeurs tout de suite, en général en haut de mon fichier, pour des raisons de clarté et de maintenance du code. Ça permet d’avoir la liste explicite des valeurs qui sont contenus dans mon reactiveValues.
Ensuite, je remplis ma valeur :
observe({
if (file.exists("logs.csv")) {
Sys.sleep(2)
values$logs <- read.table(
"logs.csv",
sep = ",",
colClasses = "character",
col.names = c("clic", "n", "time")
)
} else {
NULL
}
}) Ça c’est un bout de code qui va être lu dès le début (puisqu’il s’agit d’un observe) et qui sera jamais relu ensuite parce qu’il n’y a pas d’entrée réactive à l’intérieur.
Je le mets simplement pour lire le fichier, s’il existe, au démarrage de la session.
Petite subtilité
Puisque values$logs est une variable réactive, pourquoi ce bout de code n’est pas réexécuté quand values$logs change ?
En fait, Shiny va automatiquement faire la distinction selon qu’on assigne une valeur à values$logs (donc on écrit values$logs <- ...) ou bien si on utilise values$logs à l’intérieur d’un calcul.
Dans le premier cas, on ne veut pas redéclencher le calcul du bloc de code, sinon on serait bloqué dans une boucle infinie où on recalcule values$logs à chaque fois.
Dans le deuxième cas, le calcul sera effectivement redéclenché comme pour une variable réactive classique. Dans notre exemple, on retrouve ce cas dans le bloc de output$logs_table
Là, de nouveau, je pourrais faire autrement, par exemple on peut le mettre directement dans le reactiveValues. Ça donnerait :
values <- reactiveValues(
logs = if (file.exists("logs.csv")) {
Sys.sleep(2)
read.table("logs.csv", sep = ",", colClasses = "character", col.names = c("clic", "n", "time"))
} else {
NULL
}
) Là on est vraiment sur du niveau de détails. En terme de performance, ça ne va avoir aucun impact. C’est purement du goût personnel et une manière d’organiser le code.
Moi j’aime bien initialiser mes variables dans le reactiveValues avec des NULL, et je les remplis ensuite dans le reste de l’application.
Finalement, le troisième bloc de code :
observeEvent(input$submit, {
log <- data.frame(
clic = "submit",
n = input$submit,
time = as.character(Sys.time())
)
write.table(log,
file = "logs.csv",
sep = ",",
append = TRUE,
row.names = FALSE,
col.names = FALSE)
if (is.null(values$logs)) {
values$logs <- log
} else {
values$logs <- rbind(
values$logs,
log
)
}
})Dans ce bloc de code, on a réuni les deux étapes qu’on faisait avant dans un bloc observeEvent puis dans un bloc eventReactive.
Le problème de compétitivité pour savoir qui sera calculé le premier entre observeEvent et eventReactive ne se pose plus du tout puisqu’on fait les deux étapes dans le même bloc, à la suite.
C’est un gros avantage d’utiliser reactiveValues, puisqu’on peut tout mettre dans un seul bloc observe (ou observeEvent).
Finalement, on modifie directement le jeu de données. On fait un rbind pour rajouter la nouvelle ligne.
Pas besoin de repasser par la case lecture du fichier CSV.
Résultat : L’application est beaucoup plus fluide.
À retenir :
- On utilise
reactiveValuesquand on souhaite modifier le jeu de données par la suite et que refaire le calcul d’origine n’est soit pas possible, ou pas souhaitable pour des raisons de performance. - Un
reactiveValuess’initialise comme une liste. C’est une liste de valeurs réactives indépendantes les unes des autres qu’on va pouvoir utiliser et manipuler tout au long de l’application. - Assigner une valeur à
values$logs<-ne crée pas de réactivité. C’est seulement quand on va utiliser la variable dans un calcul qu’elle va être réactive.
La fonction isolate()
Bon.
On a vu le plus dur.
La fonction isolate() est très simple : Elle permet de supprimer temporairement la nature réactive d’une entrée réactive.
Si j’écris isolate(input$filtre), ça va utiliser la valeur contenue dans cet objet. Si input$filtre change dans l’application, alors ce bloc de code ne sera pas recalculé parce qu’on a utilisé isolate().
J’ai une petite confession à vous faire sur cette fonction.
En écrivant cet article, ça m’a fait énormément réfléchir sur la manière dont j’utilise les outils la réactivité en Shiny.
Je partais avec certaines idées que j’ai remises en question durant l’écriture.
Et là, je suis en train de chercher des exemples avec isolate().
Pas juste des exemples théoriques limités pour montrer comment la fonction marche. Vous savez lire la documentation.
On est là pour savoir précisément dans quelle situation vous devez utiliser telle ou telle fonction.
Eh ben là, j’arrive pas à trouver de problèmes où utiliser isolate() est pertinent.
J’ai parcouru plein d’anciens projets de code, et à chaque fois j’utilise isolate() pour de mauvaises raisons. Parce que j’ai mal codé. Je crée de la dette technique.
Typiquement, j’utilise un reactiveValues() au lieu d’un reactive(). Ça complexifie mon code sans raison et je me retrouve à devoir utiliser isolate().
Conclusion : On utilise isolate() par facilité.
Parce que ça peut permettre de trouver une solution rapide et simple à un problème de réactivité.
Et en soi, ce n’est pas une mauvaise raison. Mais il faut garder à l’esprit qu’on crée une dette qu’on devra payer plus tard.
Avec du code convolué.
Donc utilisez cette fonction avec parcimonie. Si vous voyez que vous l’utilisez à tout va, posez-vous la question s’il n’y a pas un meilleur moyen. Par meilleur moyen, j’entends :
- Du code plus facile à maintenir.
- Et du code plus performant.
Si à un moment je trouve une utilisation particulièrement pertinente à cette fonction, je reviendrai sur cette section. Je suis aussi ouvert à vos suggestions dans les commentaires !
La fonction req()
Si la fonction is.null() est votre fonction la plus utilisée dans une appli Shiny, alors vous allez aimer cette section.
req(), pour require, permet de ne pas poursuivre la lecture du code tant que la variable à l’intérieur de req() ne vaut pas une valeur autre que :
NULLFALSE""(chaîne de caractère vide)- Un vecteur vide
0dans l’unique cas où il s’agit d’uninputse rapportant à unactionButton
Même si 90% du temps vous allez l’utiliser pour le cas spécifique où la variable vaut NULL, il ne faut pas oublier les autres cas.
Parfois la valeur FALSE est une valeur légitime. Dans ce cas, vous n’échapperez pas au is.null().
Je vous propose de prendre une version légèrement modifiée du premier exemple que nous avons étudié :
server <- function(input, output, session) {
output$ui_species <- renderUI({
selectInput(
inputId = "species",
label = "Species",
choices = unique(iris$Species)
)
})
data <- reactive({
subset(
iris,
Species == input$species
)
})
output$plot <- renderPlot({
plot(
x = data()$Sepal.Length,
y = data()$Sepal.Width,
)
})
}
ui <- fluidPage(
titlePanel("iris"),
sidebarLayout(
sidebarPanel(
uiOutput("ui_species"),
),
mainPanel(
plotOutput("plot")
)
)
)
shinyApp(ui, server)La seule différence, c’est qu’au lieu de spécifier directement le selectInput dans la partie UI, j’utilise un uiOutput et je définis mon filtre dans la partie serveur.
C’est assez commun de procéder ainsi dès que les paramètres du filtre en question dépendent de variables qui n’existent que du côté serveur.
Ici c’est pas vraiment justifié, mais ça suffira pour montrer ce que je veux montrer.
Si on n’est pas trop attentif quand on démarre l’application, on ne voit pas trop de différence par rapport à la première appli.
Rafraîchissez la page plusieurs fois.
Vous allez voir qu’au chargement initial, un message d’erreur apparaît, mais qu’il est très rapidement remplacé par le graphique.
La raison ?
Quand Shiny va lire ce morceau de code :
data <- reactive({
subset(
iris,
Species == input$species
)
}) L’entrée input$species n’existe pas encore.
Elle est créé une fraction de seconde plus tard. Ce qui redéclenche le calcul des données et finit par afficher le graphique.
Mais ça explique le clignotement furtif de l’erreur.
Dans ce cas, c’est seulement un clignotement de message d’erreur.
C’est la honte mais ça passe encore.
Dans d’autres situations, ça va juste faire planter l’appli.
Le réflexe du noob, c’est de rajouter un test :
if (!is.null(input$species)) {
...
}Eh bien non, Shiny vous donne une fonction bien plus pratique :
data <- reactive({
subset(
iris,
Species == req(input$species)
)
}) En utilisant req(), Shiny va vérifier si input$species est une valeur égale à NULL.
Si oui, alors il va couper court à tout calcul et s’arrêter là. Il reviendra quand il aura une valeur.
Je vous conseille d’user et d’abuser de req(), ça va rendre vos applications plus robustes.
Dans ce petit exemple, on devrait aussi le mettre dans les appels à data() :
output$plot <- renderPlot({
plot(
x = req(data())$Sepal.Length,
y = req(data())$Sepal.Width,
)
}) À retenir
req()permet de rendre votre code plus robuste. Utilisez le à volonté !- On oublie vite que
req()ne teste pas que la valeurNULL, mais aussiFALSE,"", etc. Gardez ça en tête.
Mes petites astuces autour de la réactivité
On en a à présent terminé avec les fonctions de réactivité !
Dans ce chapitre, j’ai envie de vous montrer les quelques astuces que j’utilise ici et là et qui me facilitent pas mal la vie.
Ce ne sont pas des secrets de développeurs, mais plutôt des trucs où on peut facilement passer à côté, voire même des astuces un peu sales.
Comment forcer la réactivité avec Sys.time()
On commence d’ailleurs par une astuce sale.
Franchement, quand je fais ça, je me dis que je crée de la dette technique.
Mais vraiment c’est bien pratique.
Je donne un exemple plus bas dans la section sur les filtres interdépendants.
L’idée, c’est de forcer la réactivité.
Vous avez une variable réactive et vous voulez garantir sa modification.
values$filter_ready <- Sys.time()La fonction Sys.time() permet de donner une valeur que vous n’avez encore jamais donnée auparavant.
Bah oui parce que avant c’était le passé.
On n’a jamais été maintenant avant maintenant, si vous préférez.
Je l’utilise en général de deux manières différentes :
- Soit sur un data.frame réactif. Je rajoute une nouvelle colonne :
df$update <- Sys.time(). - Ou bien sur des variables de transition (comme dans l’exemple plus bas sur les filtres interdépendants). Ces variables me permettent de dire qu’un bloc est terminé et que je veux en démarrer un nouveau.
Comment accélérer un calcul avec bindCache
Ce n’est pas tout à fait une astuce, mais c’est nouveau, donc peut-être que vous ne connaissez pas encore.
Cette fonction existe depuis shiny 1.6 et permet de retenir le résultat d’un reactive() dans le cache.
Elle va être particulièrement utile si les conditions suivantes sont réunies :
- Le calcul de la variable réactive est long. Le but c’est avant tout d’améliorer la performance.
- Les mêmes calculs (à partir des mêmes entrées réactives) sont souvent répétés.
- La variable réactive dépend de relativement peu d’entrées (ça rejoint le point précédent).
On va enregistrer le résultat d’un calcul.
Reprenons l’exemple de base mais en simulant un calcul long pour le reactive() :
library(magrittr)
server <- function(input, output, session) {
data <- reactive({
Sys.sleep(5)
subset(
iris,
Species == input$species
)
}) %>% bindCache(input$species)
output$plot <- renderPlot({
plot(
x = data()$Sepal.Length,
y = data()$Sepal.Width,
)
})
}
ui <- fluidPage(
titlePanel("iris"),
sidebarLayout(
sidebarPanel(
selectInput(
inputId = "species",
label = "Species",
choices = unique(iris$Species)
)
),
mainPanel(
plotOutput("plot")
)
)
)
shinyApp(ui, server)Si l’appli n’a jamais été lancée, alors elle va prendre 5 secondes pour calculer data().
Pour être plus précis, on devrait dire : « Si le processus R n’est pas encore créé ».
Idem à chaque changement de filtre.
Mais dès que data() aura été calculée pour un filtre, alors le calcul n’aura jamais lieu de nouveau puisqu’il aura été enregistré !
À retenir
bindCache()permet d’enregistrer des valeurs réactives en cache pour améliorer la performance de votre application.- Attention à bien réfléchir à la pertinence de
bindCache()dans votre contexte. Il ne faut surtout pas l’ajouter automatiquement à tous vosreactive()!
Comment avoir plusieurs inputs dans un observeEvent
Bon.
Je vais peut-être passer pour un débile, mais j’ai mis longtemps à découvrir cette “astuce”.
Comme on écrit tout le temps :
observeEvent(input$submit, {
...
})Je pensais qu’on ne pouvait mettre qu’une seule variable pour déclencher le calcul du observeEvent !
Mais pas du tout !
Vous pouvez très bien écrire :
observeEvent({
input$submit1
input$submit2
}, {
...
})Ou bien (c’est différent) :
observeEvent(c(
input$submit1
input$submit2
), {
...
})Ainsi, votre observeEvent sera calculé à chaque fois qu’une des deux variables sera modifiée !
Attention toutefois : On a deux manières d’écrire qui ont deux comportements différents.
Vous savez que par défaut, ignoreNULL = TRUE, pour la fonction observeEvent.
Dans la première situation, si une des deux variables vaut NULL, alors le code ne sera pas lu.
Il faudra que les deux variables soient différentes de NULL pour déclencher le calcul.
Dans le second cas, on n’a pas ce comportement puisque :
> c(1, NULL)
[1] 1En effet, un vecteur qui contient une valeur NULL n’est pas NULL. La valeur NULL est juste virée.
Donc si une des deux variables vaut NULL, le code peut tout de même être lu.
Voilà.
Deux situations, deux conséquences.
À vous de voir ce qui vous va le mieux.
Et bien sûr, c’est aussi valable pour eventReactive.
Cas d'usage: Dans un shinydashboard
Dans les sections suivantes, je vais répertorier les cas d’usage les plus courants.
Comme ça, la prochaine fois que vous vous retrouvez dans cette situation, vous pourrez revenir ici et trouver des solutions.
Je souhaite aussi compléter ce chapitre au fil du temps lorsque je rencontre de nouvelles situations.
D’ailleurs, si vous avez un problème ou des questions sur la réactivité, n’hésitez pas à laisser un commentaire en bas de la page !
Je serais ravi de vous donner un coup de main, et potentiellement de compléter le guide avec votre exemple !
On commence par un exemple simple et classique : shinydashboard.
Typiquement, vous avez des onglets dans la barre de menu à gauche.
Et chaque onglet va vous présenter un ensemble de tableaux, graphiques, cartes, et autres visualisations.
Évidemment, chaque dashboard est unique, et à l’intérieur d’une page, on peut trouver moults complications.
Ces complications sont traitées dans les sections suivantes (ou alors, expliquez-moi votre situation en commentaire).
L’idée de base d’un dashboard est simple : Tant qu’on n’entre pas sur une page, inutile de charger les données de cette page.
La plupart des utilisateurs ne vont même pas visiter tous les menus. Ils vont aller directement à celui qui les intéresse, et c’est tout.
Voici un squelette de code simple :
library(shinydashboard)
ui <- dashboardPage(
dashboardHeader(title = "Dashboard"),
dashboardSidebar(
sidebarMenu(
menuItem("iris", tabName = "iris"),
menuItem("mtcars", tabName = "mtcars")
)
),
dashboardBody(
tabItems(
tabItem(tabName = "iris",
plotOutput("plot_iris")),
tabItem(tabName = "mtcars",
plotOutput("plot_mtcars"))
)
)
)
server <- function(input, output, session) {
data_tab1 <- reactive({
Sys.sleep(5)
iris
})
data_tab2 <- reactive({
Sys.sleep(5)
mtcars
})
output$plot_iris <- renderPlot({
plot(
x = data_tab1()$Sepal.Length,
y = data_tab1()$Sepal.Width
)
})
output$plot_mtcars <- renderPlot({
plot(
x = data_tab2()$wt,
y = data_tab2()$mpg
)
})
}
shinyApp(ui, server)Essayez l’application par vous-même.
Elle met simplement ce principe fondamental en Shiny : Tant que l’onglet n’est pas cliqué, on ne demande pas l’affichage des sorties.
En corollaire, on ne demande pas le chargement des données.
On le remarque bien parce que j’ai mis des délais de 5 secondes sur chaque menu.
On attend 5 secondes au démarrage. Et tant qu’on ne clique pas sur le 2e menu, on n’a pas les 5 secondes de chargement supplémentaires.
C’est aussi valable avec les tabsetPanel d’ailleurs.
Le problème dans Shiny, c’est qu’on n’a jamais du code qui est aussi simple.
Je vous vois arriver tout de suite. « Mais oui mais moi c’est pas pareil à cause que… ».
Non.
Y’a pas de à cause que.
Le code va évidemment être plus compliqué.
Vous allez avoir plusieurs jeux de données, plein de sorties, peut-être même des onglets dans la page, etc.
On pense souvent à l’envers quand on fait du Shiny. On veut que Shiny s’adapte à notre logique de pensée. Non. Adaptez votre logique de pensée à Shiny.
Le principe de base : Tant que la page n’est pas affichée, on ne charge pas les données.
Et pour ça, votre meilleur ami est la fonction reactive().
Créez une fonction reactive() par page. Ou même créez-en plusieurs.
Mais n’utilisez pas la même fonction reactive() qui contient plusieurs objets pour plusieurs pages.
En bonus : Si votre jeu de données est souvent le même, utilisez bindCache.
Cas d'usage: Les filtres interdépendants
Un cas d’usage super classique, mais néanmoins particulièrement complexe, va être dans le cas de filtres interdépendants.
Par filtres interdépendants, j’entends le fait que sélectionner un premier filtre va influencer les choix des autres filtres.
Dans cette section, j’utilise des exemples volontairement simplistes pour qu’on puisse y comprendre quelque chose.
Même si votre application est complexe, essayez de vous ramener à un raisonnement simple.
Qui dépend de quoi ?
Autre chose : J’utilise le terme filtre parce que c’est ce qui est le plus courant. Mais en fait, je fais référence à n’importe quelle entrée réactive. Par exemple, ça peut être un jeu de données réactif.
Si vous pensez que votre situation est différente, laissez-moi un petit commentaire et je jetterai un coup d’œil (Sauf si votre fichier fait 5000 lignes. Essayez de créer un exemple reproductible).
On va démarrer avec une question Stackoverflow :
Shiny Interdependent Filters values.
En fait la question ne nous intéresse pas, puisque personne n’a mentionné le problème sous-jacent que nous allons discuter.
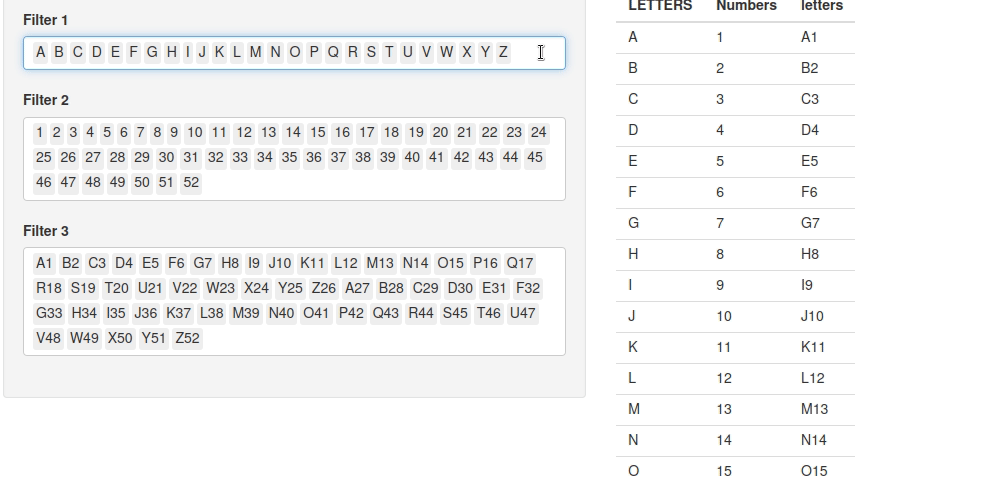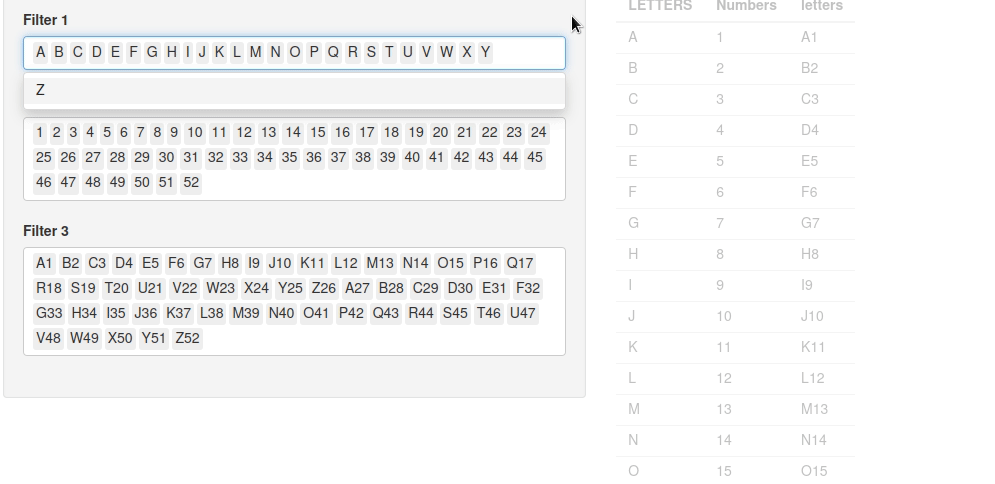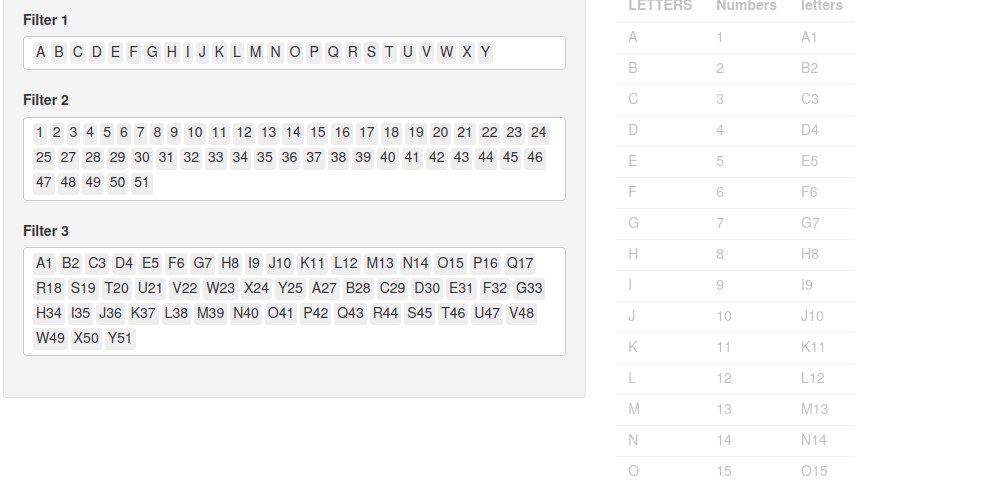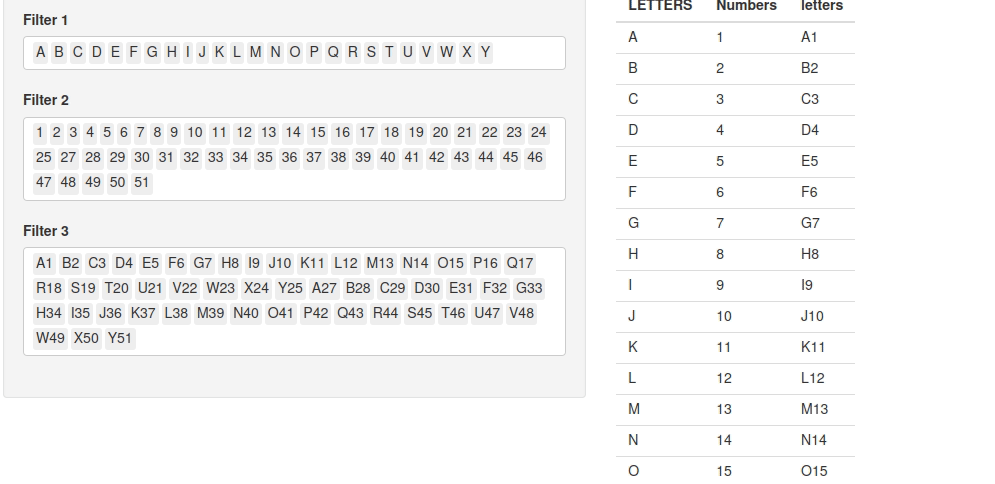
D’abord, voyons le code, que j’ai légèrement retouché (pour le simplifier et supprimer les dépendances) :
df <- data.frame(
LETTERS = rep(LETTERS, 2),
Numbers = as.character(1:52),
letters = paste(LETTERS, as.character(1:52), sep = "")
)
ui <- fluidPage(
sidebarLayout(
sidebarPanel(
selectInput(
inputId = "filter1",
label = "Filter 1",
choices = LETTERS,
selected = LETTERS,
multiple = TRUE
),
selectInput(
inputId = "filter2",
label = "Filter 2",
choices = df$Numbers,
selected = df$Numbers,
multiple = TRUE
),
selectInput(
inputId = "filter3",
label = "Filter 3",
choices = df$letters,
selected = df$letters,
multiple = TRUE
)
),
mainPanel(
tableOutput("tableprint")
)
)
)
server <- function(input, output, session) {
observe({
dt <- df$Numbers[df$LETTERS %in% input$filter1]
updatePickerInput(session, "filter2", choices = dt, selected = dt)
})
observe({
dt <- df$letters[df$Numbers %in% input$filter2]
updatePickerInput(session, "filter3", choices = dt, selected = dt)
})
output$tableprint <- renderTable({
Sys.sleep(2)
df <- df[df$LETTERS %in% input$filter1,]
df <- df[df$Numbers %in% input$filter2,]
df <- df[df$letters %in% input$filter3,]
df
})
}
shinyApp(ui = ui, server = server)J’ai fait un autre changement : J’ai rajouté un délai de 2 secondes au chargement du tableau.
Toujours pour la même raison : on imagine que ce soit un tableau long à calculer.
Bon.
Essayez d’utiliser l’application et changez juste un filtre.
Vous allez voir le tableau qui va se recharger trois fois d’affilée :
Super la performance ! Il va être content l’utilisateur.
Pourquoi ça fait ça ?
- Quand on change le premier filtre, ça déclenche le calcul de
output$tableprint. Ça c’est pour le premier chargement. - Sauf que ça déclenche aussi le premier
observe, qui va modifierinput$filter2. Et commeinput$filter2est modifié, ça redéclencheoutput$tableprint. - Finalement, le deuxième
observeest lui aussi recalculé (commeinput$filter2a changé), donc rebelotte, on recalcule le tableau.
Comme je l’ai déjà dit, il y a des tonnes de manière de faire la même chose en Shiny. Mais il y a certaines manières qui sont plus performantes que d’autres.
Quand les données sont légères et qu’il n’y a qu’un seul utilisateur, ça va.
Mais gardez en tête que même un ralentissement de 100 millisecondes peut vous poser des problèmes.
Les ralentissement sont amplifiés par la taille des données, le nombre d’utilisateurs concurrents, et les répétitions des calculs.
Notre exemple est simpliste, mais il y a en fait plein de situations différentes, qui ont chacune une solution la plus adaptée :
- Supprimer l’interdépendance. C’est ce que vous allez trouver sur beaucoup de sites web. Par exemple : booking.com. Si les filtres choisis n’aboutissent sur aucun résultat, on n’affiche aucun résultat. Potentiellement ça donne lieu à des choix de filtres incohérents.
- Ajouter un bouton. Au lieu d’avoir un tableau qui réagit directement aux filtres, on ajoute un bouton et on attend que l’utilisateur clique dessus pour déclencher le calcul du tableau. Les choix proposés dans les filtres restent interdépendants (ou non) pendant que l’utilisateur fait ses choix.
- Filtres emboîtés avec garantie de changement. Ici les filtres sont emboîtés comme des poupées russes. Filtre 1 va influencer les choix de Filtre 2. Filtre 2 va influencer les choix de Filtre 3. Mais pas l’inverse. Donc on pourrait mettre un
observeEvent(input$filtre_3)puisque tout changement de filtre va éventuellement changer Filtre 3 et on en est sûr. - Filtres emboîtés sans garantie de changement. On verra dans cette solution un autre exemple où les filtres sont emboîtés, mais changer Filtre 1 ne garantit pas que Filtre 3 va changer. On ne marche pas encore sur la tête, mais on n’est pas loin ! Le pire : Cette situation est bien plus courante que vous n’imaginez.
- Si les filtres sont rapides à calculer. Si vous souhaitez garder l’interdépendance, ne pas ajouter de boutons, et que vos filtres ne sont pas emboîtés, mais qu’ils sont rapides à calculer, et que Mercure est alignée avec Venus, alors j’ai une solution pour vous.
Solution 1 : Supprimer l’interdépendance
C’est le plus simple. On vire les observe :
df <- data.frame(
LETTERS = rep(LETTERS, 2),
Numbers = as.character(1:52),
letters = paste(LETTERS, as.character(1:52), sep = "")
)
ui <- fluidPage(
sidebarLayout(
sidebarPanel(
selectInput(
inputId = "filter1",
label = "Filter 1",
choices = LETTERS,
selected = LETTERS,
multiple = TRUE
),
selectInput(
inputId = "filter2",
label = "Filter 2",
choices = df$Numbers,
selected = df$Numbers,
multiple = TRUE
),
selectInput(
inputId = "filter3",
label = "Filter 3",
choices = df$letters,
selected = df$letters,
multiple = TRUE
)
),
mainPanel(
tableOutput("tableprint")
)
)
)
server <- function(input, output, session) {
output$tableprint <- renderTable({
Sys.sleep(2)
df <- df[df$LETTERS %in% input$filter1,]
df <- df[df$Numbers %in% input$filter2,]
df <- df[df$letters %in% input$filter3,]
df
})
}
shinyApp(ui = ui, server = server)Rien de super spécial ici.
Ça marche comme avant, sauf que le tableau ne se recharge pas 3 fois de suite.
Et, évidemment, les filtres ne sont plus interdépendants.
Par contre, vous remarquerez que si on change plein de valeurs d’affilées, ça recharge à chaque fois.
C’est là que le bouton trouve son utilité.
Solution 2 : Ajouter un bouton
df <- data.frame(
LETTERS = rep(LETTERS, 2),
Numbers = as.character(1:52),
letters = paste(LETTERS, as.character(1:52), sep = "")
)
ui <- fluidPage(
sidebarLayout(
sidebarPanel(
selectInput(
inputId = "filter1",
label = "Filter 1",
choices = LETTERS,
selected = LETTERS,
multiple = TRUE
),
selectInput(
inputId = "filter2",
label = "Filter 2",
choices = df$Numbers,
selected = df$Numbers,
multiple = TRUE
),
selectInput(
inputId = "filter3",
label = "Filter 3",
choices = df$letters,
selected = df$letters,
multiple = TRUE
),
actionButton("submit", "Submit")
),
mainPanel(
tableOutput("tableprint")
)
)
)
server <- function(input, output, session) {
data <- eventReactive(input$submit, {
Sys.sleep(2)
df <- df[df$LETTERS %in% input$filter1,]
df <- df[df$Numbers %in% input$filter2,]
df <- df[df$letters %in% input$filter3,]
df
}, ignoreNULL = FALSE)
observe({
dt <- df$Numbers[df$LETTERS %in% input$filter1]
updateSelectInput(session, "filter2", choices = dt, selected = dt)
})
observe({
dt <- df$letters[df$Numbers %in% input$filter2]
updateSelectInput(session, "filter3", choices = dt, selected = dt)
})
output$tableprint <- renderTable({
data()
})
}
shinyApp(ui = ui, server = server)Ici je rajoute un eventReactive qui permet de mettre à jour les données seulement quand on clique sur le bouton.
Le reste du temps, il n’y a que les filtres qui se mettent à jour de manière interdépendantes.
Évidemment, on peut aussi combiner les deux solutions : Ajouter un bouton et supprimer l’interdépendance.
De manière générale j’aime bien la solution du bouton dès que l’application utilise des volumes importants de données et de nombreux filtres.
Ça simplifie énormément les choses.
Et côté utilisateur, ça se passe bien aussi.
Vous noterez que j’ai aussi séparé le calcul des données et le rendu du tableau.
J’aime bien que chaque chose soit à sa place. On ne mélange pas la manipulation de données et le calcul des sorties.
Si toutefois vous tenez à tout mélanger, alors il faut faire attention et bien faire la distinction entre les deux blocs de code suivants :
observeEvent(input$submit, {
output$tableprint <- renderTable({
Sys.sleep(2)
df <- df[df$LETTERS %in% input$filter1,]
df <- df[df$Numbers %in% input$filter2,]
df <- df[df$letters %in% input$filter3,]
df
})
})et
observeEvent(input$submit, {
Sys.sleep(2)
df <- df[df$LETTERS %in% input$filter1,]
df <- df[df$Numbers %in% input$filter2,]
df <- df[df$letters %in% input$filter3,]
output$tableprint <- renderTable({
df
})
})Même s’ils se ressemblent beaucoup, ces deux blocs sont fondamentalement différents, et vous allez trouver un comportement très différent sur l’appli.
Dans le premier cas, on crée une sortie réactive qui dépend des entrées réactives des filtres. Ça veut dire que le tableau va se mettre à jour quand on change les filtres !
Ce qui n’est pas du tout ce qu’on pensait faire.
Le bouton submit permet seulement de recréer l’assignation de la sortie réactive, mais il n’apporte rien de spécial.
Dans le deuxième cas, la sortie réactive output$tableprint ne dépend plus du tout des filtres. Il utilise un data.frame qui est recalculé seulement quand on clique sur le bouton.
Je vous invite à essayer par vous-même et faire vos propres tests.
Solution 3 : Filtres emboîtés avec garantie de changement
Cette fois-ci, on va utiliser une particularité de notre exemple :
- Filtre 3 dépend de Filtre 2 qui dépend de Filtre 1.
- Si on change n’importe quel filtre, alors Filtre 3 est garanti d’être modifié.
Si la 2e condition n’est pas respectée, on va voir comment faire en Solution 4.
Donc si on change n’importe quel filtre, Filtre 3 va forcément être modifié à la fin des haricots.
Ça peut paraître un cas particulier qui n’arrive jamais, mais en fait si, ça arrive régulièrement, surtout quand on souhaite avoir des filtres qui dépendent les uns des autres.
Typiquement, Filtre 1 correspond au pays, Filtre 2 correspond à la région, et Filtre 3 correspond à la ville.
On peut même imaginer dans cette situation que tant que Filtre 1 n’est pas renseigné, alors Filtre 2 ne propose aucun choix.
Dans ce cas, c’est facile, il suffit juste d’utiliser Filtre 3 comme s’il s’agissait d’un bouton.
df <- data.frame(
LETTERS = rep(LETTERS, 2),
Numbers = as.character(1:52),
letters = paste(LETTERS, as.character(1:52), sep = "")
)
ui <- fluidPage(
sidebarLayout(
sidebarPanel(
selectInput(
inputId = "filter1",
label = "Filter 1",
choices = LETTERS,
selected = LETTERS,
multiple = TRUE
),
selectInput(
inputId = "filter2",
label = "Filter 2",
choices = df$Numbers,
selected = df$Numbers,
multiple = TRUE
),
selectInput(
inputId = "filter3",
label = "Filter 3",
choices = df$letters,
selected = df$letters,
multiple = TRUE
)
),
mainPanel(
tableOutput("tableprint")
)
)
)
server <- function(input, output, session) {
data <- eventReactive(input$filter3, {
Sys.sleep(2)
df <- df[df$LETTERS %in% input$filter1,]
df <- df[df$Numbers %in% input$filter2,]
df <- df[df$letters %in% input$filter3,]
df
}, ignoreNULL = FALSE)
observe({
dt <- df$Numbers[df$LETTERS %in% input$filter1]
updateSelectInput(session, "filter2", choices = dt, selected = dt)
})
observe({
dt <- df$letters[df$Numbers %in% input$filter2]
updateSelectInput(session, "filter3", choices = dt, selected = dt)
})
output$tableprint <- renderTable({
data()
})
}
shinyApp(ui = ui, server = server)Ce code ressemble quasiment à celui de l’exemple précédent, mais avec input$filtre3 à la place du bouton, et on a complètement supprimé le bouton.
Dans ce contexte particulier, il s’agit de la meilleure solution.
C’est suffisamment fluide pour l’utilisateur et on ne recharge pas 36 fois le tableau pour rien.
Solution 4 : Filtres emboîtés sans garantie de changement
Pour illustrer ce cas, on va devoir choisir un autre exemple.
Un exemple où :
- Les filtres sont emboîtés, comme dans l’exemple précédent.
- Le plus petit filtre n’est pas garanti de changer si on change n’importe quel autre filtre.
Voici l’exemple :
df <- read.csv("https://www.charlesbordet.com/assets/udemy/datascience-r/data.frames/indicateurs.csv")
server <- function(input, output, session) {
# Update list of years
observeEvent({
input$indicator
input$country
}, {
list_year <- subset(df, country == input$country &
!is.na(df[[input$indicator]]))$year
updateSelectInput(session, "year", choices = list_year)
})
# Update data
data <- reactive({
df <- subset(df,
country == input$country &
year == input$year)
df$y <- df[[input$indicator]]
df
})
# Plot data
output$text <- renderText({
Sys.sleep(2)
data()$y
})
}
ui <- fluidPage(
titlePanel("Hello"),
sidebarLayout(
sidebarPanel(
selectInput(
inputId = "indicator",
label = "Indicator:",
choices = c("CO2.emissions", "fertility.rate", "GDP", "life.expectancy", "population")
),
selectInput(
inputId = "country",
label = "Country:",
choices = unique(df$country)
),
selectInput(
inputId = "year",
label = "Year:",
choices = 1960:2011
)
),
mainPanel(
uiOutput("text")
)
)
)
shinyApp(ui, server)On utilise un jeu de données qui contient des indicateurs tels que le PIB, les émissions de CO2 ou le taux de natalité de plein de pays pour plein d’années différentes.
On sélectionne l’indicateur, le pays, l’année, et on obtient la valeur de l’indicateur.
Problème : Les données ne sont pas disponibles pour tous les pays pour toutes les années. Il y a pas mal de données manquantes.
On évite à l’utilisateur de choisir une combinaison qui n’existe pas en s’assurant de proposer une liste des années pour laquelle il y aura forcément des données.
Par exemple : Les émissions de CO2 pour l’Afghanistan ne sont disponibles qu’entre 1960 et 2011. Le PIB est lui disponible jusqu’en 2014.
Le terme interdépendance est peut-être trop fort dans ce cas, mais on a bien un filtre (year) qui dépend des autres filtres (indicator et country).
Si vous jouez un peu avec l’application, vous n’allez peut-être pas vous rendre compte du problème immédiatement (parce qu’il y a peu de données manquantes).
Mais il existe bel et bien :
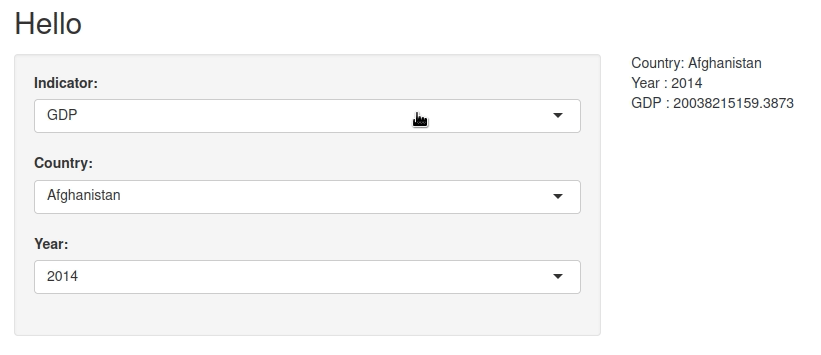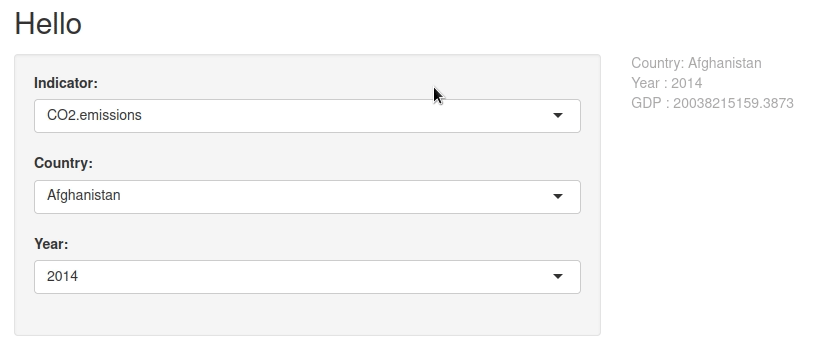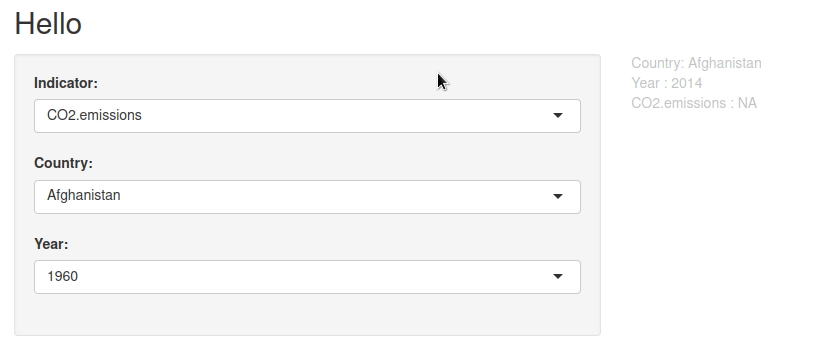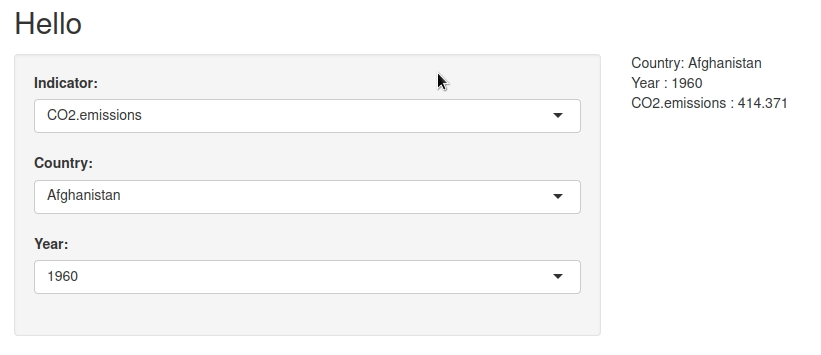
On s’en aperçoit quand on change d’indicateur et que l’année qui était en sélection n’est plus disponible.
La logique est la suivante :
- Le
observeEventprovoque la demande de mise à jour deinput$year - En attendant,
data()est mis à jour. - Toujours en attendant,
output$textest mis à jour. On voit le NA apparaître. - Ça y est,
input$yeara été mis à jour ! - En conséquence,
data(), puisoutput$textsont re-calculés.
D’où le double-chargement. Et le NA qui apparaît. Ou l’erreur, selon le contexte. Voire le crash dans certains cas.
Bon, bah c’est simple, pour éviter le double-chargement, on fait comme avant : On conditionne uniquement sur input$year vu qu’il va forcément changer si on change les autres filtres !
Hm ?
Ou pas.
Si on prend l’année 1960 par exemple, qui est disponible pour le PIB et les émissions de CO2, la valeur n’est pas mise à jour.
C’est l’objet de cette section : Il n’y a pas de garantie que la valeur du filtre va changer.
Donc si on retire la réactivité sur data(), la sortie ne sera pas du tout mise à jour.
Ce cas est compliqué parce qu’on a besoin de la réactivité sur data() ET input$year mais ces deux entrées réactives ne changent pas simultanément.
Il y a un léger délai entre les deux, ce qui provoque ce double chargement.
C’est pénible à la fin !
Comment ils font dans les autres langages ? (En vrai je sais pas, je suis preneur de vos retours)
Et puis franchement, dans ce cas, est-ce qu’on a envie de rajouter un bouton ? Ou de laisser l’utilisateur deviner quelles sont les combinaisons qui sont manquantes en supprimant l’interdépendance ?
On pourrait.. mais si on peut éviter c’est mieux.
Le problème est dans le fait que le changement des deux entrées n’est pas simultané.
On va donc le rendre simultané en utilisant une petite astuce avec reactiveValues :
df <- read.csv("https://www.charlesbordet.com/assets/udemy/datascience-r/data.frames/indicateurs.csv")
server <- function(input, output, session) {
values <- reactiveValues(
year = NULL # Buffer variable for input$year
)
observe({
values$year <- input$year # Update buffer variable
})
# Update list of years
observeEvent({
input$indicator
input$country
}, {
list_year <- subset(df, country == input$country &
!is.na(df[[input$indicator]]))$year
updateSelectInput(session, "year", choices = list_year)
values$year <- as.character(list_year[1])
})
# Update data
data <- reactive({
df <- subset(df,
country == input$country &
year == values$year)
df$y <- df[[input$indicator]]
df
})
# Plot data
output$text <- renderText({
Sys.sleep(2)
data()$y
})
}
ui <- fluidPage(
titlePanel("Hello"),
sidebarLayout(
sidebarPanel(
selectInput(
inputId = "indicator",
label = "Indicator:",
choices = c("CO2.emissions", "fertility.rate", "GDP", "life.expectancy", "population")
),
selectInput(
inputId = "country",
label = "Country:",
choices = unique(df$country)
),
selectInput(
inputId = "year",
label = "Year:",
choices = 1960:2011
)
),
mainPanel(
textOutput("text")
)
)
)
shinyApp(ui, server)J’ai rajouté une variable réactive values$year qui va en gros prendre le rôle de input$year.
Au début :
values <- reactiveValues(
year = NULL # Buffer variable for input$year
)
observe({
values$year <- input$year # Update buffer variable
}) Ce morceau de code me permet en gros de remplacer input$year par values$year. Si je m’arrêtais là, ça ne servirait à rien de spécial, mais l’appli marcherait toujours.
La grosse différence se situe ici :
observeEvent({
input$indicator
input$country
}, {
list_year <- subset(df, country == input$country &
!is.na(df[[input$indicator]]))$year
updateSelectInput(session, "year", choices = list_year)
values$year <- as.character(list_year[1])
})Il y a toujours le updateSelectInput qui va me permettre de mettre à jour l’interface.
Le changement, c’est surtout que je peux modifier values$year immédiatement !
Problème de simultanéité ou de délai ? Réglé !
Il ne reste plus qu’à changer tous les input$year en values$year et le tour est joué.
Petite subtilité
Vous vous demandez peut-être pourquoi j'ai ajouté as.character().
Il faut absolument que values$year soit identique à la future valeur de input$year. Sinon, Shiny va détecter un changement et recharger la sortie.
Or, dans ce cas, input$year est en character par défaut. Je dois donc m'assurer que values$year le soit aussi.
Solution 5 : Si les filtres sont rapides à calculer
Si on ne souhaite pas supprimer l’interdépendance, ni ajouter un bouton, et qu’on n’est pas dans le cas de filtres interdépendants emboîtés, comment on fait ?
Bon.
Là c’est plus compliqué.
Mais j’ai pensé très fort et j’ai trouvé quelques solutions.
De manière générale, ça fait appel à deux principes :
- On doit tester si un filtre est « prêt », c’est-à-dire si sa valeur est finale ou s’il va être modifié à cause d’un autre filtre. C’est tout le problème de l’interdépendance.
- On doit garantir que le calcul des données n’est pas fait tant que tous les filtres ne sont pas prêts.
Voici ma proposition :
df <- data.frame(
LETTERS = rep(LETTERS, 2),
Numbers = as.character(1:52),
letters = paste(LETTERS, as.character(1:52), sep = "")
)
ui <- fluidPage(
sidebarLayout(
sidebarPanel(
selectInput(
inputId = "filter1",
label = "Filter 1",
choices = LETTERS,
selected = LETTERS,
multiple = TRUE
),
selectInput(
inputId = "filter2",
label = "Filter 2",
choices = df$Numbers,
selected = df$Numbers,
multiple = TRUE
),
selectInput(
inputId = "filter3",
label = "Filter 3",
choices = df$letters,
selected = df$letters,
multiple = TRUE
)
),
mainPanel(
tableOutput("tableprint")
)
)
)
server <- function(input, output, session) {
values <- reactiveValues(
filter1_choices = LETTERS,
filter2_choices = df$Numbers,
filter3_choices = df$letters,
filter_ready = NULL # Indicate if filters are finished computing
)
observeEvent({
input$filter1
input$filter2
}, {
filter2_choices <- df$Numbers[df$LETTERS %in% input$filter1]
if (!setequal(filter2_choices, values$filter2_choices)) {
updateSelectInput(
session,
inputId = "filter2",
choices = filter2_choices,
selected = filter2_choices
)
values$filter2_choices <- filter2_choices
return(NULL)
}
filter3_choices <- df$letters[df$Numbers %in% input$filter2]
if (!setequal(filter3_choices, values$filter3_choices)) {
updateSelectInput(
session,
inputId = "filter3",
choices = filter3_choices,
selected = filter3_choices
)
values$filter3_choices <- filter3_choices
return(NULL)
}
values$filter_ready <- Sys.time()
})
data <- eventReactive(values$filter_ready, {
print("compute data")
Sys.sleep(2)
df <- df[df$LETTERS %in% input$filter1,]
df <- df[df$Numbers %in% input$filter2,]
df <- df[df$letters %in% input$filter3,]
df
})
output$tableprint <- renderTable({
print("compute table")
data()
})
}
shinyApp(ui = ui, server = server)Laissez-moi vous guider dans le code.
Dans un premier temps, j’initialise des valeurs réactives :
values <- reactiveValues(
filter1_choices = LETTERS,
filter2_choices = df$Numbers,
filter3_choices = df$letters,
filter_ready = NULL # Indicate if filters are finished computing
)Les trois premières variables vont me permettre d’enregistrer la liste des choix des filtres.
En confrontant la liste des choix présente avec la liste des choix future, je vais pouvoir déterminer si un filtre est prêt ou non.
En gros, un filtre est prêt si la liste des choix présente est égale à la liste des choix future.
La dernière variable est un intermédiaire permettant de déclencher le calcul des données une fois que tous les filtres sont prêts.
Le gros du travail se trouve dans le deuxième bloc :
observeEvent({
input$filter1
input$filter2
input$filter3
}, {
filter2_choices <- df$Numbers[df$LETTERS %in% input$filter1]
if (!setequal(filter2_choices, values$filter2_choices)) {
updateSelectInput(
session,
inputId = "filter2",
choices = filter2_choices,
selected = filter2_choices
)
values$filter2_choices <- filter2_choices
return(NULL)
}
filter3_choices <- df$letters[df$Numbers %in% input$filter2]
if (!setequal(filter3_choices, values$filter3_choices)) {
updateSelectInput(
session,
inputId = "filter3",
choices = filter3_choices,
selected = filter3_choices
)
values$filter3_choices <- filter3_choices
return(NULL)
}
values$filter_ready <- Sys.time()
}) Ce bloc va être relu à chaque fois que les filtres sont modifiés.
Le problème qu’on avait avant, c’était que les données étaient calculés immédiatement après qu’un filtre change.
Ici c’est différent.
On va parcourir les filtres un par un.
Si le filtre est « prêt », donc si sa liste de choix a déjà été mise à jour, alors on continue.
Sinon, alors on met à jour sa liste de choix, puis on recommence de zéro.
Pour « recommencer de zéro », j’utilise return(NULL). Ça sert à arrêter la lecture du code. Comme je viens de modifier un input, le bloc observe() va être redéclencher.
Et ainsi de suite, jusqu’à ce que tous les filtres soient prêts.
À ce moment-là, je change la valeur de values$filter_ready en utilisant l’astuce avec Sys.time().
Le calcul des données est alors déclenché, puis la mise à jour du tableau.
On pourrait aussi se passer de la variable intermédiaire et tout mettre dans le observe(), mais on y perd en organisation du code.
C’est pas mal, non ?
Ça marche, mais c’est pas parfait.
Le plus gros reproche qu’on pourrait faire, c’est que si la liste des choix des filtres est longue à calculer, alors le recalcul systématique va être peu performant.
Dans ce dernier cas, on peut être plus malin.
Par exemple avec des variables intermédiaires qui enregistrent le fait qu’un filtre est « prêt », et on invalide ces variables après la mise à jour du tableau.
On peut aussi essayer de mettre à jour simultanément tous les filtres d’un coup, au lieu de le faire de manière séquentielle.
Mais on crée alors un autre problème : Il y a un délai entre l’appel à updateSelectInput et la mise à jour de l’input correspondant.
J’ai trouvé que c’était déjà suffisamment compliqué sans trop en rajouter.
Personnellement, je pense qu’il vaut mieux privilégier une des trois premières solutions.
Même si cette dernière solution est supposée être « sans compromis », en fait on en fait un qui est caché : On complexifie le code et on y perd en temps de maintenance.
À vous de voir.
Cas d'usage : Le reactive() qui se déclenche même si la valeur ne change pas
In Shiny, when you use observeEvent(), it listens for changes in the reactive expression provided and triggers the code inside the observer when the expression is invalidated, regardless of whether the value of the reactive expression has actually changed. This is happening in your case, where input$project_tree is changing, causing selected_node_path() to be recomputed, and observeEvent() is triggered even though the value of selected_node_path() remains the same.
One way to solve this issue is to use a reactive value to store the last known value of selected_node_path(), and then compare this with the current value inside the observer. If the values are different, only then execute the code inside the observer.
Here’s an example of how you can achieve this:
# ------ Selected node path ------------------------------------------------
selected_node_path <- eventReactive(input$project_tree, {
tree <- input$project_tree
tree$Get("path", filterFun = is_selected)[, 1]
})
# ------ Create a reactive value to store the last known value -------------
last_selected_node_path <- reactiveVal()
# ------ Update content ----------------------------------------------------
observeEvent(selected_node_path(), {
current_path <- selected_node_path()
# Check if the current path is different from the last known path
if (is.null(last_selected_node_path()) || !identical(current_path, last_selected_node_path())) {
cat(file = stderr(), "30 - Chiffrage - Update content\n")
print(current_path)
# Update the last known path with the current path
last_selected_node_path(current_path)
}
})
This approach ensures that the code inside the observer is executed only when the value of selected_node_path() changes.
Commentaires
Alex
Bonjour,
Merci pour cet article intéressant !
Il y a une petite faute dans la partie sur la fontion
req( ):“En utilisant
req(), Shiny va vérifier siinput$speciesest une valeur différente deNULL.Si oui, alors il va couper court à tout calcul et s’arrêter là. Il reviendra quand il aura une valeur.”
-> Je pense que c’est plutôt “Si non, alors il va …” -> Si elle n’est pas différente de
NULL, R arrête le calcul, et donc si oui, il ne l’arrête pas. La double négation est peut être à éliminer, je me suis embrouillé en relisant mon commentaire ^^.Juste pour info, concernant les inputs multiples dans un observeEvent, on peut utiliser list( ) en équivalent de l’accolade (que je ne connaissais pas d’ailleurs) et on obtient le même comportement, les 2 inputs doivent être non-nulles. Un ex :
observeEvent(list(input$myInput1, input$myInput2), { ... })Si je peux apporter un retour d’expérience : après plusieurs années à faire du Shiny, j’en suis venu à ne plus utiliser que observeEvent (en plus des renderCeci-ou-Cela) dans la majorité des cas. Cela me permet de mieux relire mon code car je vois directement les inputs et outputs concernés par un bout de code. J’utilisais avant reactive( ) pour les tâches récurrentes ou nécessaires dans plusieurs contextes (par exemple filtre de tableau…). Maintenant je préfère calculer la valeur ou faire le filtre dont j’ai besoin et stocker le résultat en valeur réactive, ce qui permet donc de rafraîchir tous les output concernés par le tableau lors d’action de l’utilisateur.
J’ai le sentiment que depuis mes applis sont plus robustes et “clignent” moins. Je pense clairement avoir sous exploité ces valeurs reactives pendant longtemps en faisant des fonctions reactive() pour re-calculer à différents moments la chose plutôt qu’en les stockant. Ca me semble d’autant plus intéressant quand on travaille avec une base de données et qu’on doit mettre à jour les infos après chaque enregistrement et modification de la base suite à une action de l’utilisateur.
J’ai arrêté d’utiliser
observe( )parce qu’on ne peut pas voir en un coup d’oeil ce qui est fait dans cette fonction. Du coup, la relecture de code en souffre, surtout qd ça fait des mois qu’on a pas touché à l’appli en question. Au final, j’ai fini par me dire que c’était une mauvaise pratique.Je n’ai jamais utilisé eventReactive car je n’avais pas bien compris la différence entre chacune de ces fonctions et votre article m’éclaire un peu.
Je n’ai pas la prétention de faire un guide des bonnes pratiques sous Shiny mais suis assez curieux de voir comment font les autres :-)
Cordialement.
Charles
Salut Alex, merci pour ton commentaire !
Je suis super preneur des pratiques des autres développeurs Shiny, j’ai l’impression que c’est un sujet assez peu discuté, alors qu’il est au cœur des sujets de performance/maintenability du code.
Entièrement d’accord avec toi sur seulement utiliser les observeEvent, puisque finalement la fonction observe est redondante et on noie la liste des entrées réactives à l’intérieur du code. J’aime bien l’idée d’avoir la liste des entrées au début du bloc, et observeEvent contient ce mécanisme par défaut.
J’ai eu un peu la même démarche que toi concernant les valeurs réactives (reactiveValues), mais peu à peu je reviens vers les reactive() qui simplifient beaucoup le code dans certains cas. C’est justement l’écriture de ce guide qui m’a permis de m’en rendre compte. Mais dès qu’on rentre dans quelque chose de plus complexe où on a besoin de “maîtriser” la réactivité, reactiveValues semble plus adapté. Et c’est systématiquement plus adapté dès qu’on a besoin de “modifier” la valeur plus tard (comme quand on travaille avec une base, comme tu le soulignes).
PS: Erreur corrigée, merci !
Hocine
Bonjour
Je vous remercie pour votre article,m’as vraiment aidé
J’ai juste une petite question
J’ai créé une app shiny et je voulais mettre aussi en français
App shiny avec deux langues à la fois
Est ce que y a package pour ça ou d’autres piste
Merci d’avance
DOSSI Katopé Jean
Merci beaucoup pour ce brillant cours sur les reactivités. Cependant j’aimerais que vous m’en donner beaucoup de cours sur le codage avec shiny.
DOSSI Katopé Jean
Merci beaucoup
Laisser un commentaire
Les champs obligatoires sont marqués *